Step 3: Adding external data
This is the third part of the tutorial in which we build a squid that indexes Bored Ape Yacht Club NFTs, their transfers and owners from the Ethereum blockchain, fetches the metadata from IPFS and regular HTTP URLs, stores all the data in a database and serves it over a GraphQL API. In the first two parts of the tutorial (1, 2) we created a squid that scraped Transfer events emitted by the BAYC token contract and derived some information on tokens and their owners from that data. In this part we enrich token data with information obtained from contract state calls, IPFS and regular HTTP URLs.
Prerequisites: Node.js, Subsquid CLI, Docker, a project folder with the code from the second part (this commit).
Exploring token metadata
Now that we have a record for each BAYC NFT, let's explore how we can retrieve more data for each token.
EIP-721 suggests that token metadata contracts may make token data available in a JSON referred to by the output of the tokenURI() contract function. Upon examining src/abi/bayc.ts, we find that the BAYC token contract implements this function. Also, the public ABI has no obvious contract methods that may set token URI or events that may be emitted on its change. In other words, it appears that the only way to retrieve this data is by querying the contract state.
This requires a RPC endpoint of an archival Ethereum node, but we do not need to add one here: processor will reuse the endpoint we supplied in part one of the tutorial for use in RPC ingestion.
The next step is to prepare for retrieving and parsing the metadata proper. For this, we need to understand the protocols used in the URIs and the structure of metadata JSONs. To learn that, we retrieve and inspect some URIs ahead of the main squid sync. The most straightforward way to achieve this is by adding the following to the batch handler:
processor.run(new TypeormDatabase(), async (ctx) => {
let tokens: Map<string, Token> = createTokens(rawTransfers, owners)
let transfers: Transfer[] = createTransfers(rawTransfers, owners, tokens)
+
+ let lastBatchBlockHeader = ctx.blocks[ctx.blocks.length-1].header
+ let contract = new bayc.Contract(ctx, lastBatchBlockHeader, CONTRACT_ADDRESS)
+ for (let t of tokens.values()) {
+ const uri = await contract.tokenURI(t.tokenId)
+ ctx.log.info(`Token ${t.id} has metadata at "${uri}"`)
+ }
await ctx.store.upsert([...owners.values()])
await ctx.store.upsert([...tokens.values()])
await ctx.store.insert(transfers)
})
Here, we utilize an instance of the Contract class provided by the src/abi/bayc.ts module. It uses an RPC endpoint supplied by the processor via ctx to call methods of contract CONTRACT_ADDRESS at the height corresponding to the last block of each batch. Once we have the Contract instance, we call tokenURI() for each token mentioned in the batch and print the retrieved URI.
This simple approach is rather slow: the modified squid needs about three to eight hours to get a reasonably sized sample of URIs (figure out of date). A faster yet more complex alternative will be discussed in the next part of the tutorial.
Running the modified squid reveals that some metadata URIs point to HTTPS and some point to IPFS. Here is one of the metadata JSONs:
{
"image": "https://ipfs.io/ipfs/QmRRPWG96cmgTn2qSzjwr2qvfNEuhunv6FNeMFGa9bx6mQ",
"attributes": [
{
"trait_type": "Fur",
"value": "Robot"
},
{
"trait_type": "Eyes",
"value": "X Eyes"
},
{
"trait_type": "Background",
"value": "Orange"
},
{
"trait_type": "Earring",
"value": "Silver Hoop"
},
{
"trait_type": "Mouth",
"value": "Discomfort"
},
{
"trait_type": "Clothes",
"value": "Striped Tee"
}
]
}
Note how it does not conform to the ERC721 Metadata JSON Schema.
Summary of our findings:
- BAYC metadata URIs can point to HTTPS or IPFS -- we need to be able to retrieve both.
- Metadata JSONs have two fields:
"image", a string, and"attributes", an array of pairs{"trait_type": string, "value": string}.
Once finished, roll back the exploratory code:
processor.run(new TypeormDatabase(), async (ctx) => {
let tokens: Map<string, Token> = createTokens(rawTransfers, owners)
let transfers: Transfer[] = createTransfers(rawTransfers, owners, tokens)
-
- let lastBatchBlockHeader = ctx.blocks[ctx.blocks.length-1].header
- let contract = new bayc.Contract(ctx, lastBatchBlockHeader, CONTRACT_ADDRESS)
- for (let t of tokens.values()) {
- const uri = await contract.tokenURI(t.tokenId)
- ctx.log.info(`Token ${t.id} has metadata at "${uri}"`)
- }
Extending the Token entity
We will save both image and attributes metadata fields and the metadata URI to the database. To do this, we need to add some new fields to the existing Token entity:
type Token @entity {
id: ID! # string form of tokenId
tokenId: Int!
owner: Owner!
+ uri: String!
+ image: String
+ attributes: [Attribute!]
transfers: [Transfer!]! @derivedFrom(field: "token")
}
+
+type Attribute {
+ traitType: String!
+ value: String!
+}
Here, Attribute is a non-entity type that we use to type the attributes field.
Once schema.graphql is updated, we regenerate the TypeORM data model code::
npx squid-typeorm-codegen
To populate the new fields, let us add an extra step at the end of createTokens():
async function createTokens(
ctx: Context,
rawTransfers: RawTransfer[],
owners: Map<string, Owner>
): Promise<Map<string, Token>> {
let tokens: Map<string, PartialToken> = new Map()
for (let t of rawTransfers) {
let tokenIdString = `${t.tokenId}`
let ptoken: PartialToken = {
id: tokenIdString,
tokenId: t.tokenId,
owner: owners.get(t.to)!
}
tokens.set(tokenIdString, ptoken)
}
return await completeTokens(ctx, tokens)
}
interface PartialToken {
id: string
tokenId: bigint
owner: Owner
}
Here, PartialToken stores the incomplete Token information obtained purely from blockchain events and function calls, before any state queries or enrichment with external data.
The function completeTokens() is responsible for filling Token fields that are missing in PartialTokens. This involves IO operations, so both the function and its caller createTokens() have to be asynchronous. The functions also require a batch context for state queries and logging. We modify the createTokens() call in the batch handler to accommodate these changes:
processor.run(new TypeormDatabase(), async (ctx) => {
let rawTransfers: RawTransfer[] = getRawTransfers(ctx)
let owners: Map<string, Owner> = createOwners(rawTransfers)
- let tokens: Map<string, Token> = createTokens(rawTransfers, owners)
+ let tokens: Map<string, Token> = await createTokens(ctx, rawTransfers, owners)
let transfers: Transfer[] = createTransfers(rawTransfers, owners, tokens)
Next, we implement completeTokens():
async function completeTokens(
ctx: Context,
partialTokens: Map<string, PartialToken>
): Promise<Map<string, Token>> {
let tokens: Map<string, Token> = new Map()
if (partialTokens.size === 0) return tokens
let lastBatchBlockHeader = ctx.blocks[ctx.blocks.length-1].header
let contract = new bayc.Contract(ctx, lastBatchBlockHeader, CONTRACT_ADDRESS)
for (let [id, ptoken] of partialTokens) {
let uri = await contract.tokenURI(ptoken.tokenId)
ctx.log.info(`Retrieved metadata URI ${uri}`)
let metadata: TokenMetadata | undefined = await fetchTokenMetadata(ctx, uri)
tokens.set(id, new Token({
...ptoken,
uri,
...metadata
}))
}
return tokens
}
URI retrieval here is similar to what we did in the exploration step: we create a Contract object and use it to call the tokenURI() method of the BAYC token contract. The retrieved URIs are then used by the fetchTokenMetadata() function, which is responsible for HTTPS/IPFS metadata retrieval and parsing. Once we have its output, we can create and return the final Token entity instances.
Retrieving external resources
In the fetchTokenMetadata() implementation we first classify the URIs depending on the protocol. For IPFS links we replace 'ipfs://' with an address of an IPFS gateway, then retrieve the metadata from all links using a regular HTTPS client. Here for the demonstration purposes we use the public ipfs.io gateway, which is slow and prone to dropping requests due to rate-limiting. For production squids we recommend using a dedicated gateway, e.g. from Filebase.
export async function fetchTokenMetadata(
ctx: Context,
uri: string
): Promise<TokenMetadata | undefined> {
try {
if (uri.startsWith('ipfs://')) {
const gatewayURL = path.posix.join(IPFS_GATEWAY, ipfsRegExp.exec(uri)![1])
let res = await client.get(gatewayURL)
ctx.log.info(`Successfully fetched metadata from ${gatewayURL}`)
return res.data
} else if (uri.startsWith('http://') || uri.startsWith('https://')) {
let res = await client.get(uri)
ctx.log.info(`Successfully fetched metadata from ${uri}`)
return res.data
} else {
ctx.log.warn(`Unexpected metadata URL protocol: ${uri}`)
return undefined
}
} catch (e) {
throw new Error(`Failed to fetch metadata at ${uri}. Error: ${e}`)
}
}
const ipfsRegExp = /^ipfs:\/\/(.+)$/
We use Axios for HTTPS retrieval. Install it with
npm i axios
To avoid reinitializing the HTTPS client every time we call the function we bind it to a module-scope constant:
const client = axios.create({
headers: {'Content-Type': 'application/json'},
httpsAgent: new https.Agent({keepAlive: true}),
transformResponse(res: string): TokenMetadata {
let data: {image: string; attributes: {trait_type: string; value: string}[]} = JSON.parse(res)
return {
image: data.image,
attributes: data.attributes.map((a) => new Attribute({traitType: a.trait_type, value: a.value})),
}
},
})
We move all the code related to metadata retrieval to a separate module src/metadata.ts. Examine its full contents here.
Then all that is left is to import the relevant parts in src/main.ts:
+import {TokenMetadata, fetchTokenMetadata} from './metadata'
and we are done with the processor code for this part of the tutorial. Full squid code at this point is available at this commit.
Recreate the database, rebuild the code and refresh the migrations with
docker compose down
docker compose up -d
npm run build
rm -r db/migrations
npx squid-typeorm-migration generate
npx squid-typeorm-migration apply
and test the processor by running
node -r dotenv/config lib/main.js
It runs much slower than before, requiring about three hours to get through the first batch and more than a day to sync (figures out of date). This is something we will address in the next part of the tutorial.
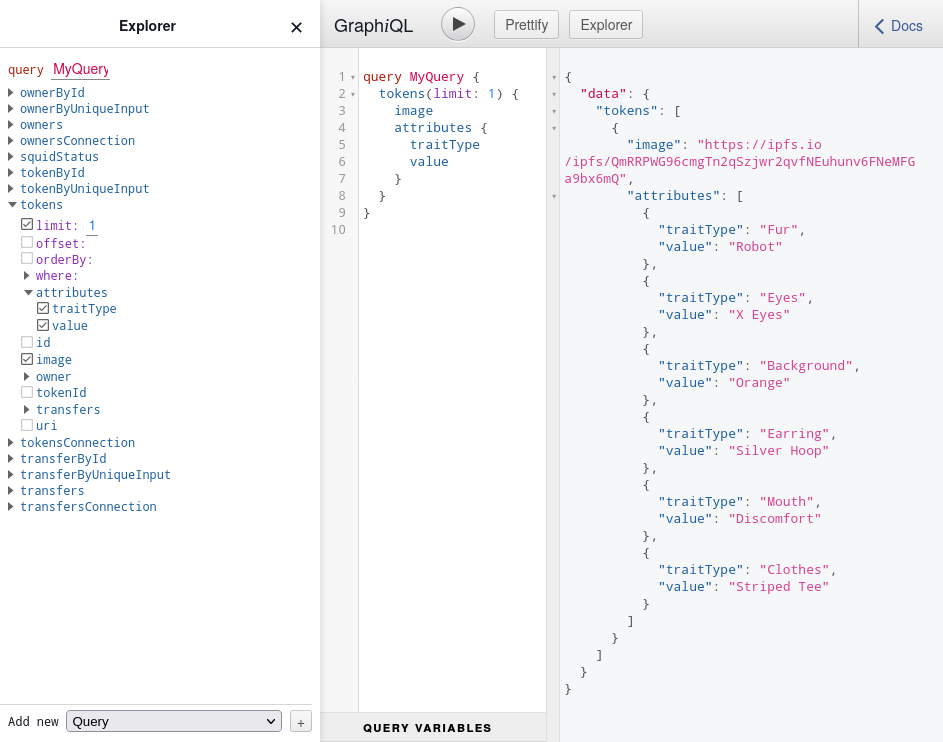
Nevertheless, the squid is already fully capable of scraping token metadata and serving it over GraphQL. Verify that by running npx squid-graphql-server and visiting the local GraphiQL playground. It is now possible to retrieve image URLs and attributes for each token: